Detect AI-generated text
Differentiate between AI-generated and human written text in a document.
GitHub Repository: View on GitHub
Introduction
I developed a machine learning system to distinguish between human-written and AI-generated text.
As large language models (LLMs) like GPT-4, LLaMA, and Cohere become more advanced, their outputs are often indistinguishable from human writing. This can cause challenges in academic, journalistic, and professional settings where content authenticity matters.
My goal was to design, implement, and evaluate methods for reliably detecting AI-generated text — even from the most modern models.
Problem
AI text detection is difficult because:
- LLMs mimic human style, coherence, and vocabulary.
- Newer models constantly evolve, producing text that bypasses older detection methods.
- Traditional statistical methods often fail to capture subtle differences.
This project set out to build a robust classifier that could:
- Work across multiple datasets.
- Adapt to newer AI models.
- Maintain high accuracy on unseen data.
Approach
1. Data
I combined multiple datasets to train and evaluate the model:
- Kaggle competition essays – 1,000 samples.
- DAIGT train dataset – 5,000 samples.
- Generated essays – 500 samples produced using GPT-4, Cohere, etc., with varied prompts and temperatures.
- Hugging Face external dataset – 15,000 samples for out-of-distribution testing.
2. Features
I engineered multiple types of features to capture both style and structure:
- Vocabulary Richness – ratio of unique words to total words.
- Readability Scores – SMOG Index, Gunning Fog Index.
- Perplexity – using GPT-2 to measure text predictability.
- Polarity & Subjectivity – sentiment-based metrics.
- Compression Factors – redundancy patterns via Lempel-Ziv and Gzip.
After analysis, I found perplexity, SMOG Index, and Gunning Fog Index were the most effective and generalizable.
3. Feature Selection
To reduce redundancy and overfitting, I performed Principal Component Analysis (PCA) and SHAP feature importance analysis.
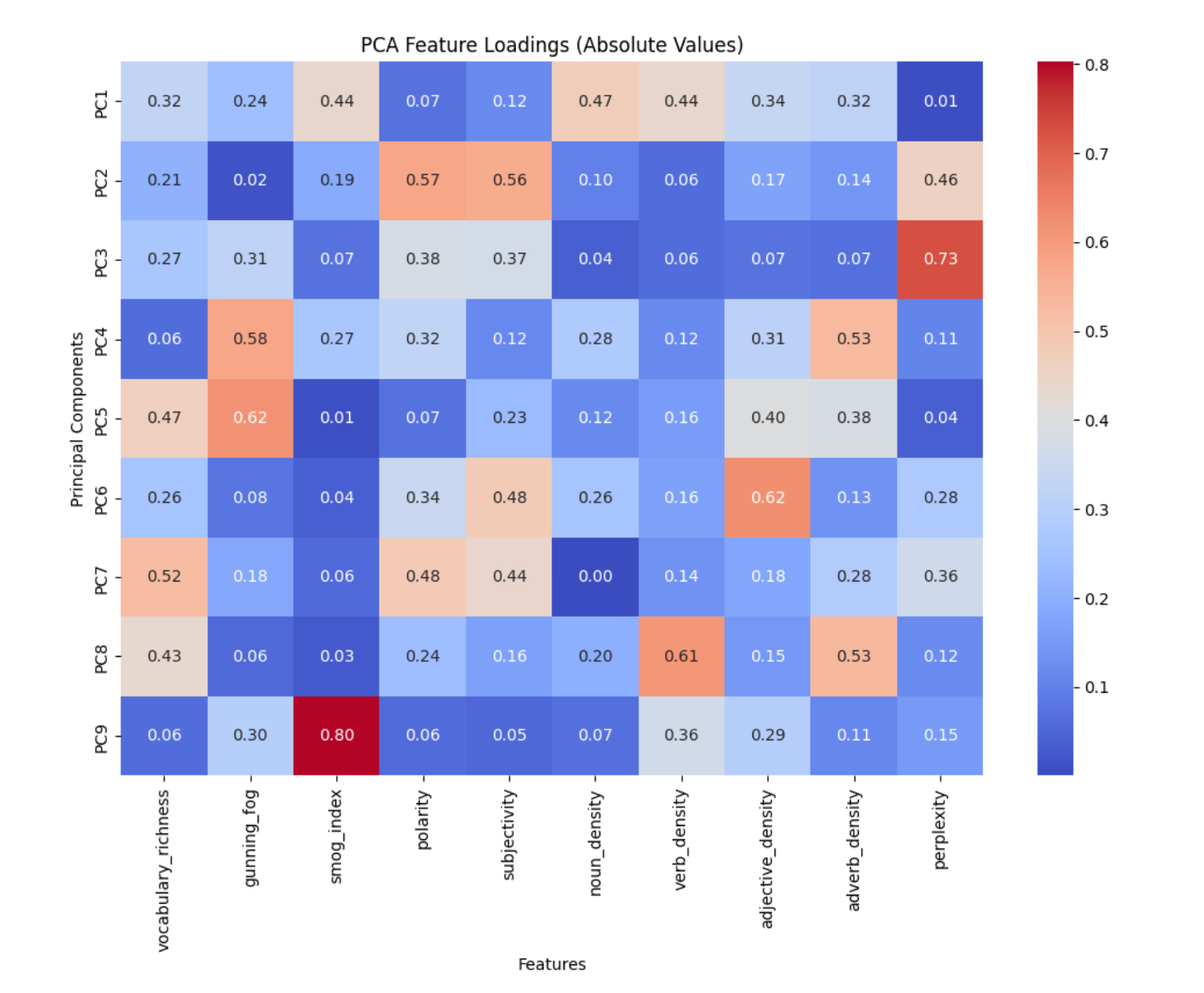
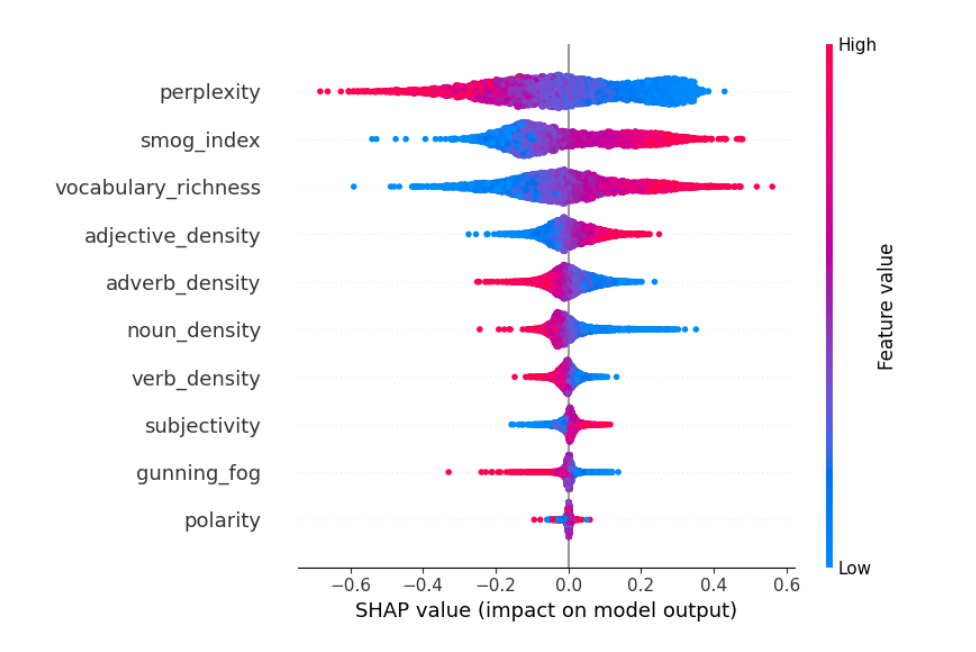
These confirmed that perplexity, SMOG Index, and Gunning Fog Index were the most influential and distinct features.
3. Models Tested
I implemented and tuned:
- Support Vector Machine (SVM)
- XGBoost
- Multi-Layer Perceptron (MLP)
I optimized each with techniques like grid search, Bayesian optimization, and early stopping.
Results
| Model | Test Accuracy | AUC-ROC | External Dataset Accuracy | External Dataset AUC-ROC |
|---|---|---|---|---|
| XGBoost | 89% | 0.95 | 81% | 0.90 |
| SVM | 87% | 0.86 | 89% | 0.89 |
| MLP | 80.7% | 0.85 | 85.5% | 0.94 |
Key Findings:
- Compression features alone performed poorly (~57% accuracy).
- Combining linguistic complexity and perplexity features gave the best results.
- The MLP with top 3 features (Perplexity, SMOG, Gunning Fog) was both accurate and generalizable.
- The model achieved 99% AUC on some external tests.
What I Solved
- Built a detection system that generalizes to data from completely new sources.
- Identified feature sets that stay effective even as AI models improve.
- Reduced overfitting by focusing on conceptually distinct features.
Conclusion
By combining linguistic readability metrics with model-based perplexity, I developed a detector that works across different datasets and AI text styles.
This project lays the groundwork for tools that maintain trust in academic, professional, and journalistic contexts.
Future Improvements
- Integrate transformer-based embeddings (BERT, RoBERTa).
- Continuously retrain on outputs from newer LLMs.
- Add semantic and discourse-level analysis.
- Deploy as a real-time detection service.